The dynamics of data accumulation
The bigger you are, the more data you can harvest. But does data accumulation necessarily breed monopolies in AI and related machine learning markets?

Each new sunrise increases the certainty that the sun will rise tomorrow. The more we know about the past, the better we can predict the future. The same holds true in important AI and related machine learning (ML) applications, where great volumes of data are needed to reach marketable levels of predictive accuracy.
To maintain dynamism in ML markets, competition authorities must thus ensure that all participants access the data they need to compete viably. But how much is enough? Is more always better, or is there a point where additional observations do little to change predictions? Do we need to observe the sun rise a billion times to know what will happen tomorrow?
Training data is a scarce resource
As detailed in a previous blog, machine learning (ML), a subfield of AI, is a prediction technology that generates new information (‘predictions’) based on existing information (‘data’). Notable ML applications include automated driving, image recognition, language processing and search. [1]
Like any product, ML models are only as good as the raw material. Access to adequate training data is critical for ML application vendors—which The Economist went as far as to qualify as “the world’s most valuable resource”.[2]

Where do ML providers and adopters obtain this valuable resource? Varian (2018) lists eight potential sources, including: as a by-product of operations (e.g. generated from machines and sensors), web scraping, data vendors (e.g. Nielsen), cloud providers (e.g. Amazon), public sector data, and offering a service (e.g. ReCAPTCHA).
Yet, despite a variety of sources, training data can be an important bottleneck for businesses trying to develop or implement ML—and an on-going concern for ML models that require regular retraining. According to a 2019 European Commission report, access to adequate training data is a key limiting factor for the development of ML applications.[3]
One particular issue is that data must be ‘big’—a term that is often used to refer to datasets for which individual observations carry little informational content, so that value is derived from having a large number of observations (Chakraborty, 2017). In many ML applications, data volume greatly affects model performance. Image recognition algorithms, for instance, must be trained on large volumes of data (Carrière-Swallow et al., 2019). The question here is: How much (relevant) data is enough to make a valuable ML model?[4]
Economies of scale and the volume of data needed
The relationship between data volume and returns from ML is a contentious topic. Hal Varian and Pat Bajari, chief economists at Google and Amazon, respectively, argue that model accuracy increases with data sample size, but at a decreasing rate.[5] Intuitively, in teaching me (or an algorithm) what Labradors looks like, the first ten Labradors are more informative than the following ten. In technical terms, data exhibits ‘decreasing returns to scale’.
Figure 1 illustrates how the value of additional dog pictures for improving a machine vision algorithm slowly diminishes as the size of the training sample increases.[6]
Figure 1. Decreasing returns to scale of Stanford Dogs data for ML accuracy
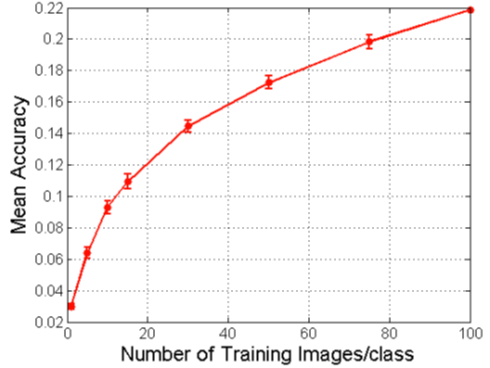
Source: Varian (2018)
If data exhibits decreasing returns to scale, then we might conclude that firms only need to secure a large-enough lump-sum of data to compete viably. Economists Ajay Agrawal, Joshua Gans, and Avi Goldfarb disagree.[7] Their argument runs as follows: even if data exhibits decreasing returns (as in Figure 1), a slight lead in data quantity may induce a slight lead in quality that attracts users. More users generate more data, which drives higher quality. This is the so-called ‘data feedback loop’ illustrated in Figure 2. Over time, a small initial data advantage can translate into a significant share of the user base and of the market. In the long run, this self-reinforcing dynamic can lead to market dominance.
In essence, Agrawal et al. distinguish between technical returns to data (i.e. accuracy) and economic returns to data (i.e. market shares), and argue that even if data exhibits decreasing returns in a technical sense (as in Figure 1), returns can be increasing in an economic sense.
Figure 2. The data feedback loop
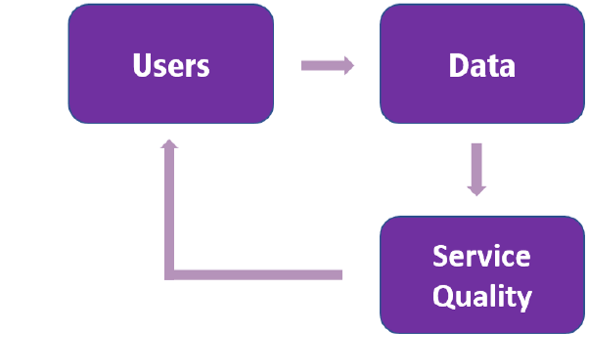
Source: based on OECD (2016)
One of the mechanisms underlying the data feedback loop relates to the increased granularity that comes with volume. Google and Microsoft’s differing views in the area of internet search ML illustrates this point.[8]
Microsoft, in justifying a 10-year deal for Yahoo search in 2009,[9] has advanced that higher performance is a direct consequence of scale.[10] Following this argument, Google search algorithm is better than Yahoo’s because more people use Google. More people using Google means that Google can collects more data and provide better search results, attracting more users, and so on. This is the feedback loop in action.
Google has expressed scepticism about Microsoft’s scale argument.[11] Yahoo’s billions of searches should be sufficient to compete effectively.[12] Yahoo’s inferior performance would reflect the lower quality of its algorithm,[13] rather than the amount of data it holds. To quote Google's Varian: “it’s not quantity or quality of the ingredients that make a difference, it’s the recipes”.
Microsoft has countered that its billions of searches are insufficient. Many queries are extremely rare and, for these queries, Google has more observation points, simply because it holds more data. Google thus produces better results for rare queries.[14]
Empirical work by Schaefler and al. (2018) vindicate Microsoft’s claims. Schaefler and al. (2018) examine the impact of additional user data on the quality of internet search results. They disentangle the effects of more data from the effect of better algorithms and find that both matter. In their oven, Varian’s analogy falls flat: both ingredients and recipe are critical to good cooking.
The Google and Microsoft disagreement also exposes the strong behavioural and structural assumptions that underlie the feedback loop argument. In the internet search case, for instance, the argument requires that (i) consumers can detect small quality differences, (ii) quality differences matters to users (or at least a few), and (iii) switching costs are sufficiently low. The same reasoning should not be expected to hold, however, in all ML markets.
In speech to text applications, for instance, it is not clear that small quality differences are obvious to the user, or that they would matter enough to justify the potentially large costs of switching providers (e.g. learning to use a new application). On the other extreme, some application areas are very sensitive to quality differences. These are applications where accuracy is a matter of life and death.[15] Who would accept a second-best medical diagnostic?[16] No one wants Dr Bing when Dr Google is down the corridor. For these applications, returns to prediction quality may amount to the whole market, i.e. “the winner takes all”.
A large share of the empirical work around returns to scale for data focuses on one ML application: internet search.[17] More research is needed to determine where the feedback loop argument holds, because the answer is likely to vary across different application area.
Economies of scope and the volume of data needed
Glen Weyl and Eric Posner present a different argument in the debate. In their 2018 book Radical Markets, the Microsoft economist and University of Chicago law professor argue that the returns to data are increasing in scale, but with a twist.
Decreasing returns to scale, they claim, only hold in pre-ML ‘standard’ statistical contexts. Standard statistics addresses relatively simple problems (e.g. estimate a population average) for which rough estimates are sufficient:
An entrepreneur who wants to open a wealth management firm in a neighbourhood wants to know whether the average income is $100,000 or $200,000 but doesn’t need to know that it is $201,000 rather than $200,000.[18]
ML tackles problems that are much more complex, according to Posner and Weyl. These new, harder tasks are more valuable than earlier, easier ones. They also call for more data, and more complex data. For these problems, the more the data, the better it can address these harder tasks. Therefore, and still following Posner and Weyl, the more the data, the more valuable it is.
To illustrate the authors’ point, consider training an ML to recognise dogs in pictures. This model requires a certain quantity of data to produce accurate results. But, as illustrated in Figure 1, the value of additional data drops past a certain threshold. However, as the volume of data continues to grow (and complexity along with it), the algorithm continues to learn. At some point, it can perform an additional, more complex task, such as labelling objects in the photographs. Again, the value of additional data for the task of labelling objects flattens out past a certain threshold. Once again, as the volume of data continues to grow, the algorithm continues to learn. At some point, it can perform an additional, even more difficult task, such as understanding the nature of the actions in the photographs.
Therefore, the value of data grows to the extent that harder problems need more data. Weyl and Posner’s argument is, implicitly, that data exhibits economies of scope. As Figure 3 illustrates, we end up with a picture that challenges Varian’s decreasing returns to scale hypothesis. Weyl and Posner note that the value of data may not increase forever: we could see a future where ML has “learned everything”. But until then, they claim, returns to the volume of data are increasing.
Figure 3. Value of data as a function of the number of observations in a typical ML
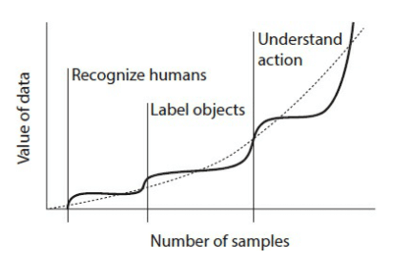
Source: Weyl and Posner (2018)
Data as a barrier to entry
Economic theory teaches us that, where there are increasing returns to scale, monopolies naturally emerge—the largest firm being the most economically efficient.[19] Likewise, where they materialise, increasing returns to scale to data could be expected to work to concentrate economic gains in the hands of data-rich firms.
Monopolisation, however, is not necessarily synonymous with monopolistic behaviour—i.e. supra-competitive pricing, reduced quality, and/or hampered innovation. So long as the market leaders are challenged by the prospect of competitive entry by other firms, monopolised markets can be competitive.
Increasing returns to scale and scope for data, however, might work in some cases to entrench the incumbent’s position by creating very high barriers to entry for prospective entrants. This could be a problem in markets where there is no substitute for a dataset that is essential, i.e. where there is only one dataset and it cannot be replicated, dispensed or purchased.[20] As US FTC Commissioner Terrell McSweeny has noted, “it may be that an incumbent has significant advantages over new entrants when a firm has a database that would be difficult, costly, or time-consuming for a new firm to match or replicate.”[21]
Incumbency advantage could be particularly pronounced in the digital space. Leading ML users were once leading data collectors, but increasingly are leading ML providers. Amazon, for instance, originally sold books as a way to gather personal data on affluent, educated shoppers (Ezrachi et al. 2016). It is now a leading provider of ML services on the cloud.
‘Data scarcity’ can seem oxymoronic. The world overflows with information—right up to toilet seats, the new data hotbed. The volume of data created and copied each year is expected to reach 44 x 1021 bytes in 2020 — 40 times more bytes than there are stars in the observable universe.[22] Yet the vast amounts of data collected online form unique sets of behavioural data that may be harder and harder to replicate in light of the self-reinforcing dynamics described above.
Why not let prospective entrants buy the necessary data in one of the many dedicated marketplaces (such as datapace.io)? A concern is that data incumbents have strong reasons not to sell their data: increasing economic returns to data tend to create perverse incentives for firms to establish a data advantage and erect barriers to entry thereafter (Cockburn et al., 2018). Incumbents might prefer hoarding the data they collect in order to, first, gain an advantage over their competitors and, later, curtail market entry (Jones et al., 2018).
Two factors that could tend to compound these challenges.
First, as previously noted, data-rich firms could benefit not only from economies of scale, but also from economies of scope. Data acquired for a particular purpose may be valuable in other contexts, granting incumbent firms an advantage over new entrants in adjacent markets (Goldfarb et al., 2018). For instance, data collected in the context of search queries can be used to inform a shopping-recommendation algorithm. Economies of scope could leave little room for potential entrants looking to grow outside the incumbents’ market segments.
Second, even if a firm successfully enters a new ML application market, incumbents may be in a position to use their rich data to detect the competitive threat, and acquire the new entrant firm before the incumbent’s position is challenged (so-called ‘killer acquisitions’).
Implications for competition policy[23]
Absent intervention, a possible market outcome could be high concentration and low contestability in data-reliant markets. This implies the need for competition policy scrutiny around data access. Should unique and non-substitutable datasets be considered an ‘essential facility’, on par with local loops for fixed telephony? Forced sharing can create inefficiencies, e.g. in the form investment disincentives, but is well established EU policy in many of the network industries. Under what conditions would the benefits of forced sharing outweigh the costs?
The emergence of ML as a general-purpose technology raises difficult empirical and normative questions. Does the relationship between data accumulation and economic returns give data-rich incumbents a significant and self-reinforcing advantage? Are competition authorities equipped to discern and analyse data-driven monopolistic returns? These questions are high on the new European Commission’s agenda,[24] and for good reasons. Monopolistic behaviour by ML providers could slow the adoption of technology critical for EU competitiveness, especially hitting those smaller firms that lack the knowledge and resources to build alternative capacity in-house. If technological revolutions are distributional earthquakes, competition authorities should work to ensure that everyone lands on their feet.
Recommended citation
Anderson, J. (2020), ‘The dynamics of data accumulation’, Bruegel Blog, 11 February. https://bruegel.org/2020/02/the-dynamics-of-data-accumulation/
[1] This post focuses on ML applications.
[2] See https://medium.economist.com/will-big-data-create-a-new-untouchable-business-elite-8dc23bcaa7cb
[3] DG COMP 2019, citing https://medium.com/machine-intelligence-report/data-not-algorithms-is-k…, https://www.edge.org/response-detail/26587, and http://www.spacemachine.net/views/2016/3/datasets-over-algorithms.
[4] While this post focuses on issues pertaining to the volume of data, other characteristics of data are just as important for generating value. These include the other so-called ‘4Vs’ of data: volume, but also velocity (i.e. frequency), variety (e.g. administrative data, social media data, pictures, etc), and veracity (i.e. representative of the target population, free of bias, etc). For a firm to have a competitive advantage over these other characteristics can also generate important economic benefits. For the purpose of this blog, I note that securing a sufficient volume of data appears to be necessary but not sufficient to having a competitive AI/ML business.
[5] Varian (2018) and Bajari et al. (2018)
[6] In particular, Bajari et al. (2018) find that the length of histories is robustly helpful in improving the demand forecast quality, but at a diminishing rate; whereas the number of products in the same category is not (with a few exceptions where it exhibits diminishing returns to scale).
[7] Agrawal, Ajay, Joshua Gans, and Avi Goldfarb. 2018a. Prediction Machines: The Simple Economics of Artificial Intelligence. Cambridge, MA: Harvard Business Review Press.
[8] As related in Goldfarb et al. (2018)
[9] See the deal’s press release: https://news.microsoft.com/2009/07/29/microsoft-yahoo-change-search-landscape/
[10] See https://www.cnet.com/news/googles-varian-search-scale-is-bogus/
[11] See Hal Varian in a CNET interview: “the scale arguments are pretty bogus in our view” (https://www.cnet.com/news/googles-varian-search-scale-is-bogus/)
[12] “the amount of traffic that Yahoo, say, has now is about what Google had two years ago” and “when we do improvements at Google, everything we do essentially is tested on a 1 percent or 0.5 percent experiment to see whether it's really offering an improvement. So, if you're half the size, well, you run a 2 percent experiment.” Source: ibid
[13] i.e. in performing tasks such as crawling, index, or ranking.
[14] The European Commission’s DG COMP made similar claims in the context of the Google Shopping case. DG COMP claimed that general search service has to receive at least a certain minimum volume of queries in order to improve the relevance of its results for uncommon queries because users evaluate the relevance of a general search service on the basis of both common and uncommon queries. See para. 288 of the EC decision (https://ec.europa.eu/competition/antitrust/cases/dec_docs/39740/39740_14996_3.pdf)
[15] Cockburn et al. (2019).
[16] An podcast episode from the Economist brings this point to life (https://www.economist.com/podcasts/2019/10/09/the-promise-and-peril-of-ai)
[17] See Schaefler and al. (2018): “In perhaps no other market has the question of the role of data stirred such a vivid discussion among industry participants, academic experts, and policy advocates than in general internet search.”
[18] Glen Weyl and Eric Posner, 2018. Radical Markets
[19] https://cs.stanford.edu/people/eroberts/cs181/projects/1997-98/microsoft-vs-doj/economics/returns.html
[20] See Calvano et al. (2020) for a survey of the literature around these issues in digital markets.
[21] Commissioner Terrell McSweeny, Opening Remarks for a Panel Discussion, “Why Regulate Online Platforms?: Transparency, Fairness, Competition, or Innovation?” at the CRA Conference in Brussels, Belgium, at 5 (Dec. 9, 2015), https://www.ftc.gov/system/files/documents/public_statements/903953/mcs….
[22] includes data generated online and by IoT and connected devices. Source: Word Economic Forum citing Raconteur (https://www.weforum.org/agenda/2019/04/how-much-data-is-generated-each-day-cf4bddf29f/)
[23] Note that a range of issues lie at the intersection of privacy and competition, including data ownership, reuse, transparency, sharing. These issues are beyond the score of this post and will not be explored here.
[24] See the mission statement of European Commission President Ursula von der Leyen, which instructs Margarethe Vestager: “In the first 100 days of our mandate, you will coordinate the work on a European approach on artificial intelligence, including its human and ethical implications. This should also look at how we can use and share non-personalised big data to develop new technologies and business models that create wealth for our societies and our businesses.” (https://ec.europa.eu/commission/sites/beta-political/files/mission-letter-margrethe-vestager_2019_en.pdf)
Bibliography
Agrawal, Ajay, Joshua Gans, and Avi Goldfarb. "Economic policy for artificial intelligence." Innovation Policy and the Economy 19.1 (2019): 139-159.
Bajari, Patrick, et al. "The impact of big data on firm performance: An empirical investigation." AEA Papers and Proceedings. Vol. 109. 2019.
Carriere-Swallow, Mr Yan, and Mr Vikram Haksar. "The economics and implications of data: an integrated perspective." (2019).
Chakraborty, Chiranjit, and Andreas Joseph. "Machine learning at central banks." (2017).
Cockburn, Iain M., Rebecca Henderson, and Scott Stern. "The impact of artificial intelligence on innovation." National Bureau of Economic Research Working Paper Series w24449 (2018).
Ezrachi, Ariel, and Maurice E. Stucke. "Virtual competition." Journal of European Competition Law & Practice 7.9 (2016): 585-586.
Goldfarb, Avi, and Daniel Trefler. "AI and international trade." National Bureau of Economic Research Working Paper Series w24254 (2018).
Jones, L. D., et al. "Artificial intelligence, machine learning and the evolution of healthcare: A bright future or cause for concern?." Bone & joint research 7.3 (2018): 223-225.
OECD. "Bringing Competition Policy to the Digital Era." (2016): 1775-1810.
Varian, Hal. "Artificial intelligence, economics, and industrial organization." National Bureau of Economic Research Working Paper Series w24839 (2018).
About the authors
Related content

The impact of COVID-19 on artificial intelligence in banking
COVID-19 has not dampened the appetite of European banks for machine learning and data science, but may in the short term have limited their artificia

Not all foreign investment is welcome in Europe
A new plan to tackle foreign subsidies would empower the European Commission to investigate foreign investments in the European Union, with Chinese in

COVID-19 credit-support programmes in Europe’s five largest economies
This paper assesses COVID-19 credit-support programmes in five of the largest European economies, and examines how countries have dealt with trade-off

Regulating big tech: the Digital Markets Act
The European Union’s proposed Digital Markets Act will attempt to control online gatekeepers by subjecting them to a wider range of upfront constraint