Some tools for lifting the patent data treasure
Bruegel contributes to the stream of research on PATSTAT by providing two algorithms that try to minimize the amount of manual work tha
Patent applications are a product of research and development, but they are also subject to research. Studying patents and the patenting behaviour of individuals and organizations is important to understand how innovation works. Indeed, the relevance of patent data has long been recognized:
Patent statistics loom up as a mirage of wonderful plentitude and objectivity. They are available; they are by definition related to inventiveness, and they are based on what appears to be an objective and only slowly changing standard.
Zvi Griliches, 1987 (Patent Statistics as Economic Indicators: A Survey)
However, data helps only if it includes the kind of information that is necessary to answer some research question. Indeed, researchers have been involved in the construction and enrichment of datasets related to patents for at least 30 years. The problems we faced in our work with patent data have roots that go back to the eighties.
First of all, not all patentees that appear in the records with the same name are the same patentee, and conversely, two different names may actually correspond to a single patentee. The parent-subsidiary structure is an additional complication for the researcher that is interested in assigning a patent to a single entity.
Because the patent office does not employ a consistent company code in its computer record, except for the “top patenting companies” where the list of subsidiaries is checked manually, the company patenting numbers produced by a simple aggregation of its computer records can be seriously incomplete.
Zvi Griliches, 1987 (Patent Statistics as Economic Indicators: A Survey)
The second problem is that patent data needs to be complemented by company data to be of most use, and efforts to obtain this kind of dataset have always required extensive manual input (see Bound et al, 1984 and Griliches, Pakes, Hall 1988)
The manual work that was cumbersome thirty years ago is even more difficult today, given that the available data is hundreds of times larger than what was in the hands of researchers in the past. Take the PATSTAT database: it is a useful source of standardized information for millions of patents from all over the world, but its usefulness is limited by the type of information that is included. For example, PATSTAT does not assign patent applicants to different categories, making it difficult to distinguish companies from public institutions or even individuals. Also, it is affected by the same problems that we mentioned above, namely the appearance of duplicates, and the missing link to other sources of firm-level data.
For this reason, some efforts are devoted to the enrichment of PATSTAT and its integration with external information. For example the EEE-PPAT table assigns a category to every patentee, establishing whether it is an individual, a company, or another kind of organization.
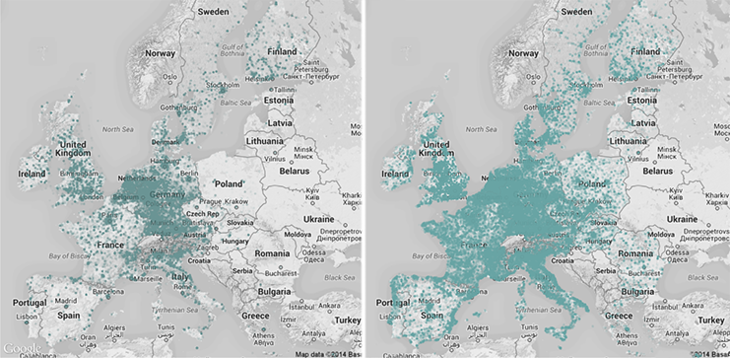
As shown in the map, we can geolocate a lot of PATSTAT patents using only information inside the database (left), but we can do much better once we link the patentees to companies, for which we have more precise information (right).
We contribute to this stream of research on PATSTAT by providing two algorithms that tackle the two above mentioned problems and that try to minimize the amount of manual work that has to be performed. We also provide data obtained by the application of these methods. Our work can be summarized as follows:
- We provide an algorithm that allows researchers to find the duplicates inside Patstat in an efficient way
- We provide an algorithm to connect Patstat to other kinds of information (CITL, Amadeus)
- We publish the results of our work in the form of source code and data for Patstat Oct. 2011.
More technically, we used or developed probabilistic supervised machine-learning algorithms that minimize the need for manual checks on the data, while keeping performance at a reasonably high level.
The data and source code is accompanied by three working papers:
A flexible, scaleable approach to the international patent “name game”
by Mark Huberty, Amma Serwaah, and Georg Zachmann
In this paper, we address the problem of having duplicated patent applicants' names in the data. We use an algorithm that efficiently de-duplicates the data, needs minimal manual input and works well even on consumer-grade computers. Comparisons between entries are not limited to their names, and thus this algorithm is an improvement over earlier ones that required extensive manual work or overly cautious clean-up of the names.
A scaleable approach to emissions-innovation record linkage
by Mark Huberty, Amma Serwaah, and Georg Zachmann
PATSTAT has patent applications as its focus. This means it lacks important information on the applicants and/or the inventors. In order to have more information on the applicants, we link PATSTAT to the CITL database. This way the patenting behaviour can be linked to climate policy. Because of the structure of the data, we can adapt the deduplication algorithm to use it as a matching tool, retaining all of its advantages.
Remerge: regression-based record linkage with an application to PATSTAT
by Michele Peruzzi, Georg Zachmann, Reinhilde Veugelers
We further extend the information content in PATSTAT by linking it to Amadeus, a large database of companies that includes financial information. Patent microdata is now linked to financial performance data of companies. This algorithm compares records using multiple variables, learning their relative weights by asking the user to find the correct links in a small subset of the data. Since it is not limited to comparisons among names, it is an improvement over earlier efforts and is not overly dependent on the name-cleaning procedure in use. It is also relatively easy to adapt the algorithm to other databases, since it uses the familiar concept of regression analysis.
About the authors
Related content

The comparison between the European and American innovation systems is hardly encouraging for Europe

Promoting STEM skills: a brief assessment of French individual learning accounts
French ILA successfully promotes basic digital skills but falls short of fostering more advanced capabilities.

The impact on the European Union of Ukraine’s potential future accession
This report evaluates the impact on the EU of a possible EU accession of Ukraine, focusing on economic consequences and institutional developments.

European natural gas imports
This dataset aggregates daily data on European natural gas import flows and storage levels.