Blogs review: Big Data, aggregates and individuals
What’s at stake: The Big Data enthusiasts compare it to a revolution. For the agnostic observer, it is interesting to move beyond this general and som
What’s at stake: The Big Data enthusiasts compare it to a revolution. For the agnostic observer, it is interesting to move beyond this general and somewhat speculative discussion and get a sense of what these massive quantities of information produced by and about people, things, and their interactions can and cannot do. In a previous review, we discussed recent applications of Big Data in the field of social science research. In this review, we consider whether and how Big Data can help complement and refine official statistics and offer ways to develop alternative measures of welfare.

Source: Manu
Big Data: revolution or evolution?
The Big Data enthusiasts call it a revolution. In 2008, Joseph Hellerstein called it the “industrial revolution of data”. Eric Brynjolsson and Andrew McAfee consider that the massive amounts of real-time data can be tracked to improve everything from websites to delivery route is the innovation story of our time. Alex (Sandy) Pentland writes that we can now use these “little data breadcrumbs” that individuals leave behind to move beyond averages and aggregates to learn more about individual behavior and networks. Ben Bernanke made a similar point in a recent speech (HT Miles Kimball) outlining that exclusive attention to aggregate numbers is likely to paint an incomplete picture of what many individuals are experiencing.
Gary King notes that Big Data is not about the data but about data analytics and paradigmatic shifts. Patrick Wolfe compares current attempts to build models of human behaviour on the basis of Big Data to the standardization of physical goods in the Industrial Revolution. Gary King says that while the data deluge does not make the scientific method obsolete, as Chris Anderson wrote in 2008, but shifts the balance between theory and empirics toward empirics in a big way.
Danah Boyd warns, however, that Big Data enhances the risk of apophenia – seeing meaningful patterns and connections where none exists. Kate Crawford cautions that relying on Big Data alone without recognizing hidden biases may provide a distorted picture while not changing the fundamental difference between correlation and causation. Danah Boyd and Kate Crawford as well as Martin Hilberg make an interesting point about the emergence of a new digital divide along data analytics capacities.
Big Data and official statistics
Big Data is relevant to the production, relevance and reliability of key official statistics such as GDP and inflation.
Michael Horrigan, the head of the Bureau of Labor Statistics (BLS) Office of Prices and Living Conditions, provides a definition that helps clarify where the border lies between Big Data and traditional data. Big Data are non-sampled data that are characterized by the creation of databases from electronic sources whose primary purpose is something other than statistical inference
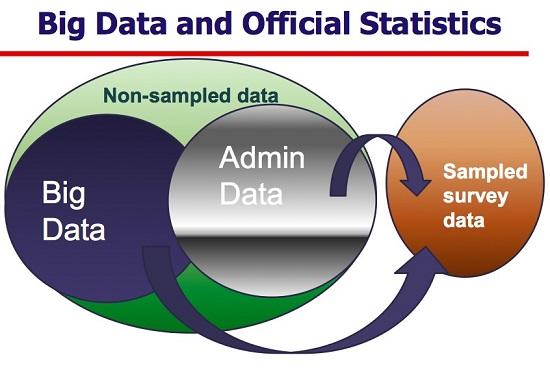
Source: Michael Horrigan
Big Data are already increasingly used to produce or complement official statistics in several advanced economies. Michael W. Horrigan, the head of the Bureau of Labor Statistics (BLS) Office of Prices and Living Conditions, describes how the BLS is already heavily relying on a large array of non-official data including corporate data to refine official economic statistics. These innovations draw on insights and web-scrapping techniques from the Billion Prices Project to track inflation in real-time, the ‘nowcasting’ research techniques developed by Hal Varian on the basis of Google searches, and the research from Matthew Shapiro that use data from Twitter accounts in a model to predict the level of initial claims for unemployment insurance. The Financial Times also reports how Maurizio Luisi and Alessandro Beber are using Big Data techniques—news mining and sentiment analysis—to build a “real-time growth index” to assess the relative strength of economic news in context and to give a snapshot of growth across leading economies.
The need for more timely and sensitive measures of economic activity in an increasingly volatile economic environment was made especially clear during the Great Recession. A recent IMF paper (Quarterly GDP Revisions in G-20 Countries: Evidence from the 2008 Financial Crisis) discussed by Menzie Chinn documents how compilation systems of quarterly GDP in most advanced countries are well designed to keep track of an economy on a steady path of growth, but are less suited for fully picking up large swings in economic activity in real-time. Early estimates of quarterly GDP become less reliable with increased economic volatility, typically requiring ex post downward post revisions during recessions and upward revisions during expansions. Brent Moulton and Dennis Fixler of the BEA note that the total revision of 2008Q4 US GDP from advance to latest is the largest downward GDP revision on record.
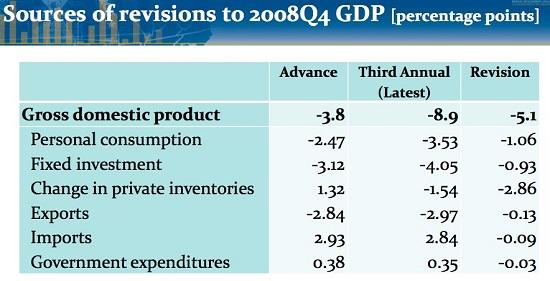
Source: BEA
Marcelo Guigale writes that similar innovations could be observed in developing countries where official statistics can be several years old. Pointing to the fact that Africans should not have to wait for a decade after a survey is fielded to adjust their country’s GDP or estimate poverty numbers, Wolgang Fengler argues that poor countries can leapfrog in the process with estimates built on the basis of Big Data. This may contribute to fixing what World Bank Chief Economist for Africa Shanta Devarajan refers to as the continent’s “statistical tragedy”. In Indonesia, joint research by the UN Global Pulse team and Crimson Hexagon found that conversation about rice on Twitter could help monitor food prices with surprising accuracy.
But the national and international statistical communities recognize the many challenges ahead, discussed during several recent events at the World Bank, the OECD in October and January, and recently during the 44th session of the United Nations Statistical Commission. A recent paper commissioned by the United Nations Economic Commissions in Europe encourages National Statistical Offices to develop internal Big Data analytical capability through specialized training. Reflecting these growing concerns among national statisticians, the 2013 International Statistical Institute’s World Statistics Congress to be held in Hong Kong in August will include a special session on Big Data and Official Statistics.
Michael Horrigan discusses the future of using Big Data by the U.S. statistical system and notes that integrating private sources of data such as Google, Intuit and Billion Prices is unlikely without more transparency from these providers. Progressing towards a better comparability of results from big data with official statistics seems more likely. Andrew Wyckoff reckons that new roles that National Statistical Offices may play in the Big Data age may include acting as a trusted certification 3rd party and issuer of best practices for data mining.
Big Data and alternative measures of welfare
Big Data may also offer ways to go beyond traditional economic statistics. Alternative measures of welfare have been used for decades, including the Human Development Index since the early 1990s, and the Kingdom of Bhutan Gross National Happiness since 1972, as well as the more recent OECD Better Life Index and Happy Planet Index. Big Data has revived some of these debates by providing new data sources and analytics tools.
Ben Bernanke said in a recent speech that we should seek better and more direct measurements of economic well-being, the ultimate objective of our policy decisions. Miles Kimball notes that these concerns echo the position of British Prime Minister David Cameron who said policymakers should focused not just on GDP but on general wellbeing, as well as former French President Nicolas Sarkozy when he pledged to fight to make all international organizations change their statistical systems by following the recommendations of the Stiglitz commission on the Measurement of Economic Performance and Social Progress.
On the recent occasion of the United Nations International Happiness Day, John Havens, founder of the H(app)athon Project, described the project’s main aim as giving “big data a direction” drawing in part on the insights of the Quantified Self movement co-founded by Wired’s founder Kevin Kelly that relies on self-monitoring and personal data collection and use. Esther Dyson predicts the emergence of a similar “Quantified Community movement”, with communities relying on their own data to measure and improve the state, health, and activities of their people and institutions.
Miles Kimball wonders how we can avoid the dangers of manipulation and politicization of new indicators of well-being and suggests that if we are going to use objective and subjective measures of well-being such as happiness and life satisfaction alongside well-seasoned measures such as GDP as ways to assess how well a nation is doing, we need to proceed in a careful, scientific way that can stand the test of time.
Data sharing and privacy
Since the bulk of Big Data is held by corporations, Robert Kirkpatrick and Patrick Meier have been promoting the concept of “data philanthropy” within the context of development and humanitarian response. Data philanthropy involves companies sharing proprietary datasets for social good. Michael Horrigan argues that it is likely that greater progress will be made using big data from businesses than households. Hal Varian discusses incentives for firms to provide data:
- Profit motive (Mastercard, Visa)
- Brand identity, thought leadership (Intuit, Monster, Zillow, Google)
- Financial reporting to investors (FedEx, UPS, retail)
The World Economic Forum proposes to provide greater individual control over data usage. The New York Times reports that Alex Pentland, an adviser to the WEF, proposes “a new deal on data” that would entail the rights to possess your data, to control how it is used, and to destroy or distribute it as one sees fit.
Felix Gillette writes in Bloomberg that at the moment, the default setting for almost everything people share online is that it will live for eternity in the cloud. In Delete: The Virtue of Forgetting in the Digital Age, Viktor Mayer-Schönberger, a lawyer and a professor at the University of Oxford, argues that this inevitably creates problems for individuals and societies that need the ability to forget in order to move forward. A perfect memory, he writes, can be paralyzing, trapping people in the past and discouraging them from trying new challenges.
Viktor Mayer-Schönberger argues that all information created online should come with customizable expiration dates. Not every piece of data would have to expire after a few seconds as photos on Snapchat do. The key, says Mayer-Schönberger, is to include some form of a self-destruct button in everything created online and to give consumers the power to tinker with the settings from the outset."